들어가며
한빛미디어에 올라온 혼공학습단 8기를 신청했는데 어쩌다 보니 선정이 되었습니다. 그래서 책 한 권을 한 달간 읽어보며 관련된 내용을 정리해보려고 합니다. 책을 공부하고 기본 미션과 선택 미션이 있는데 너무 그것만 딱하고 끝내기에는 아쉬움이 있어서 이것저것 추가해서 글을 올려보려고 합니다. 책은 제 돈으로 구매하였으며, 글의 주된 내용은 책을 기반으로 하여 작성되었습니다.
한빛미디어 - 혼자 공부하는 시리즈: 파이썬, 머신러닝, C언어, java, SQL...
프로그래밍 입문서 시장 베스트셀러 시리즈! 1:1 과외하듯 배우는 프로그래밍 언어 자습서! '무엇을', '어떻게' 학습해야 할지조차 모르는 입문자의 막연한 마음을 살펴, 친절하고 핵심적인 내용
hongong.hanbit.co.kr
- 구성
1. 내용 정리
2. 기본 미션 - 코랩 실습 화면 캡쳐 하기
3. 선택 미션 - Ch.02(02-1) 확인 문제 풀고, 풀이 과정 정리하기
1. 내용 정리 (출처: 혼자 공부하는 머신러닝+딥러닝; 한빛미디어; 2020; 박해선 저)
1) 특성: 데이터를 표현하는 하나의 성질입니다.
2) 모델 그리고 알고리즘: 머신러닝 프로그램에서는 알고리즘이 구현된 객체를 모델이라고 부릅니다. 종종 알고리즘 자체를 모델이라고 부르기도 합니다.
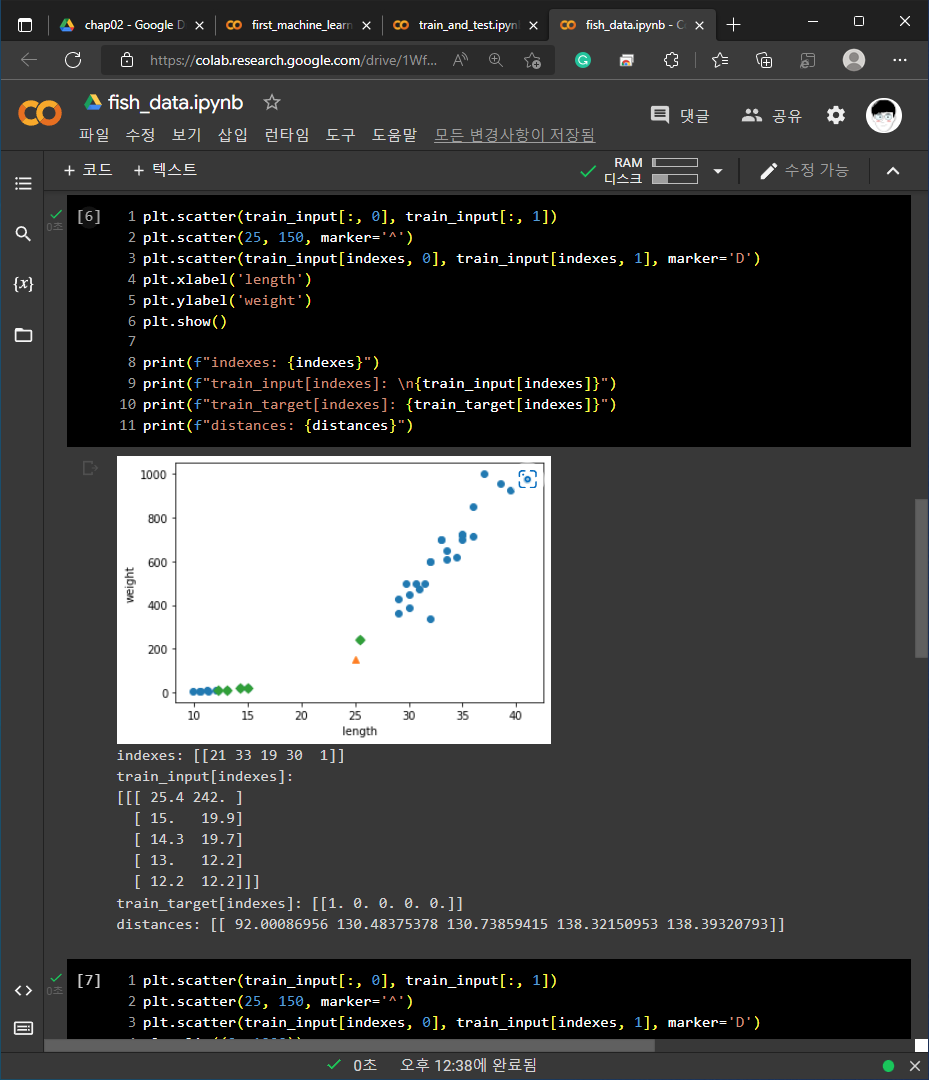
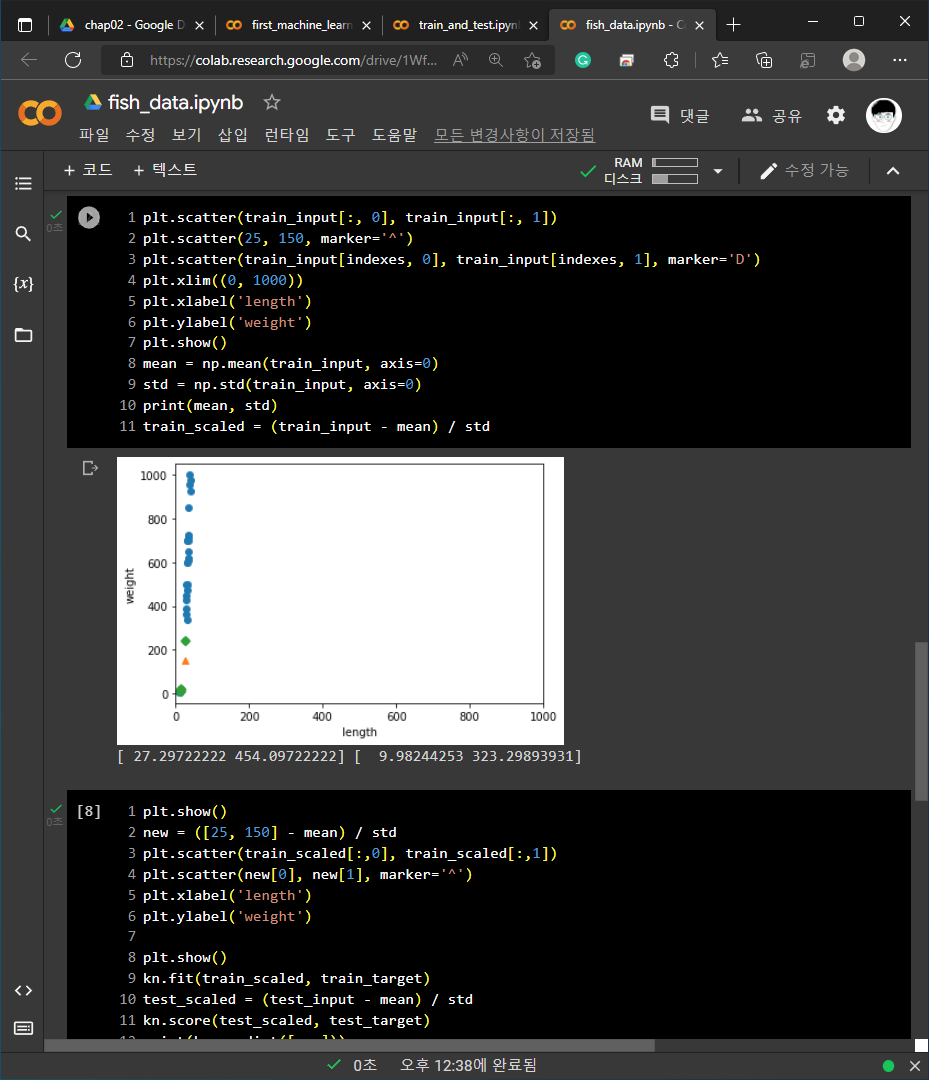
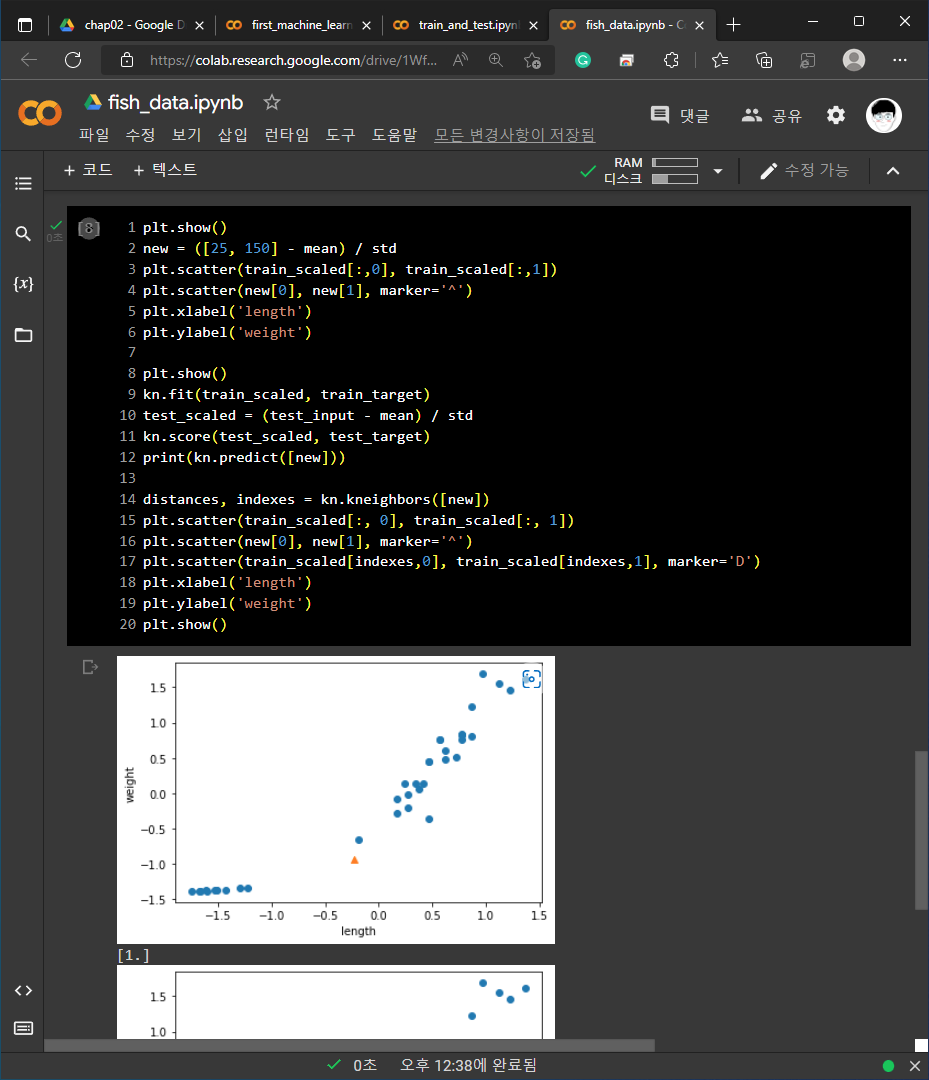
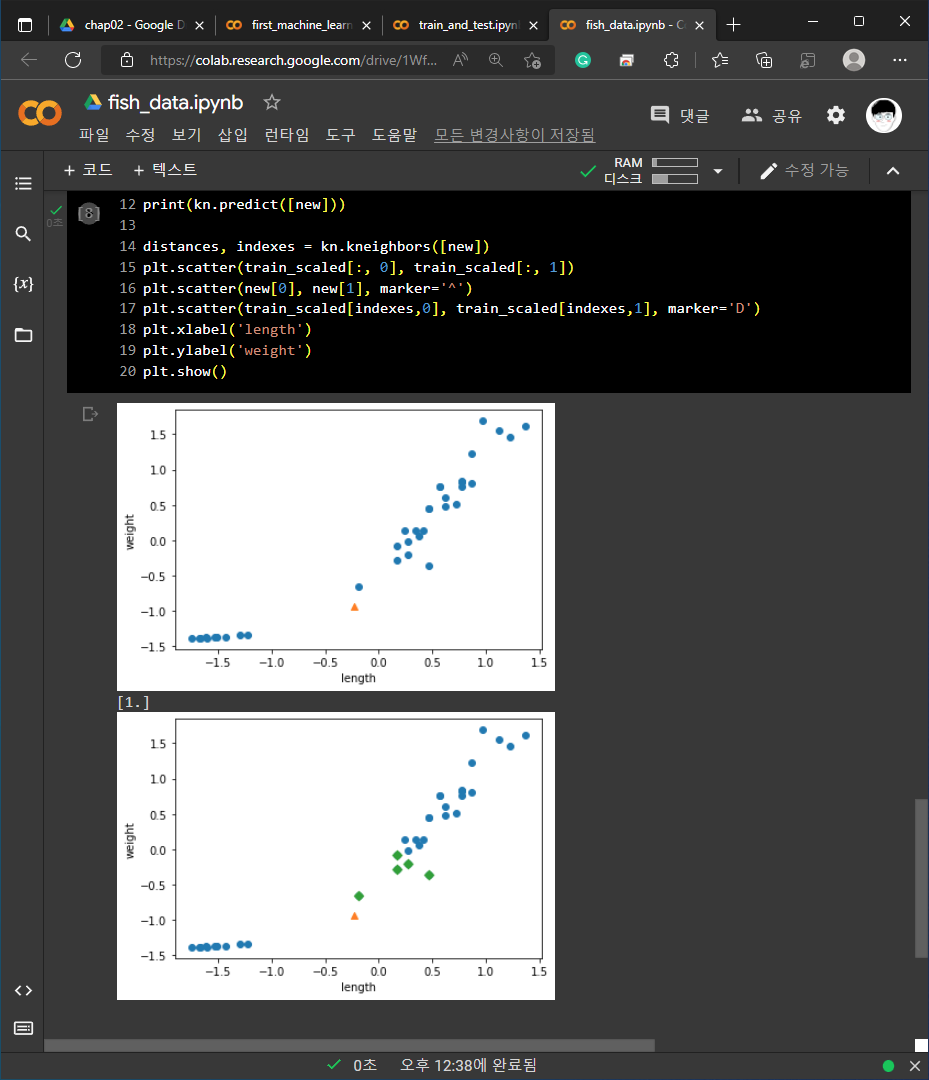
3) kNeighborsClassifier의 이웃 클래스: distances, indexes = kn.kneighbors([[25, 150]])의 형태로 코드를 작성하여 인접한 데이터들을 확인할 수 있습니다.

4) 배열과 배열을 연결하기 위해서는 np.concatenate()와 np.column_stack()을 사용할 수 있습니다.
https://numpy.org/doc/stable/reference/generated/numpy.concatenate.html
numpy.concatenate — NumPy v1.23 Manual
numpy.org
https://numpy.org/doc/stable/reference/generated/numpy.column_stack.html
numpy.column_stack — NumPy v1.23 Manual
numpy.org
5) 브로드 캐스팅
- 크기가 다른 넘파이 배열에서 자동으로 사칙 연산을 모든 행이나 열로 확장하여 수행하는 기능입니다.
- 평균과 표준편차를 계산할 때 행을 따라서 열의 통계 값을 계산하기 위해서는 axis=0을 설정합니다.
https://numpy.org/doc/stable/user/basics.broadcasting.html
Broadcasting — NumPy v1.23 Manual
The basic operation of vector quantization calculates the distance between an object to be classified, the dark square, and multiple known codes, the gray circles. In this simple case, the codes represent individual classes. More complex cases use multiple
numpy.org
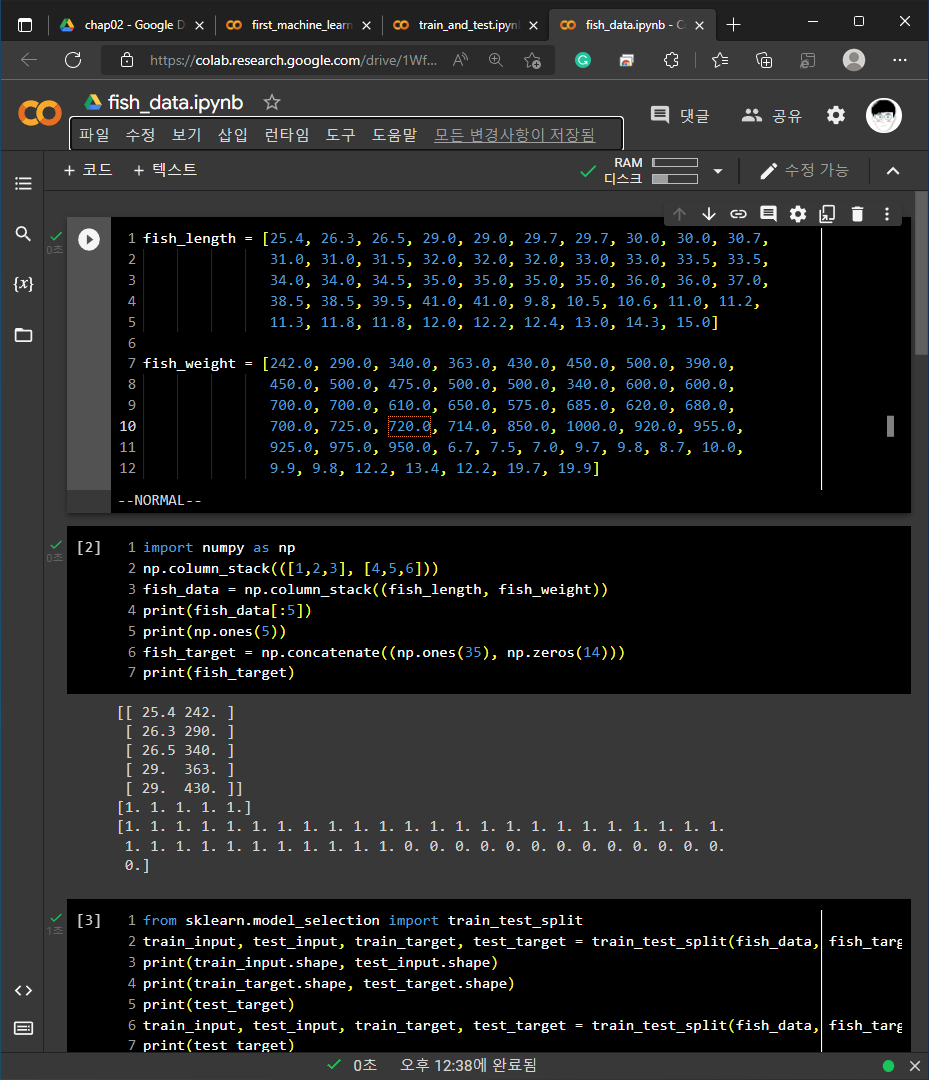
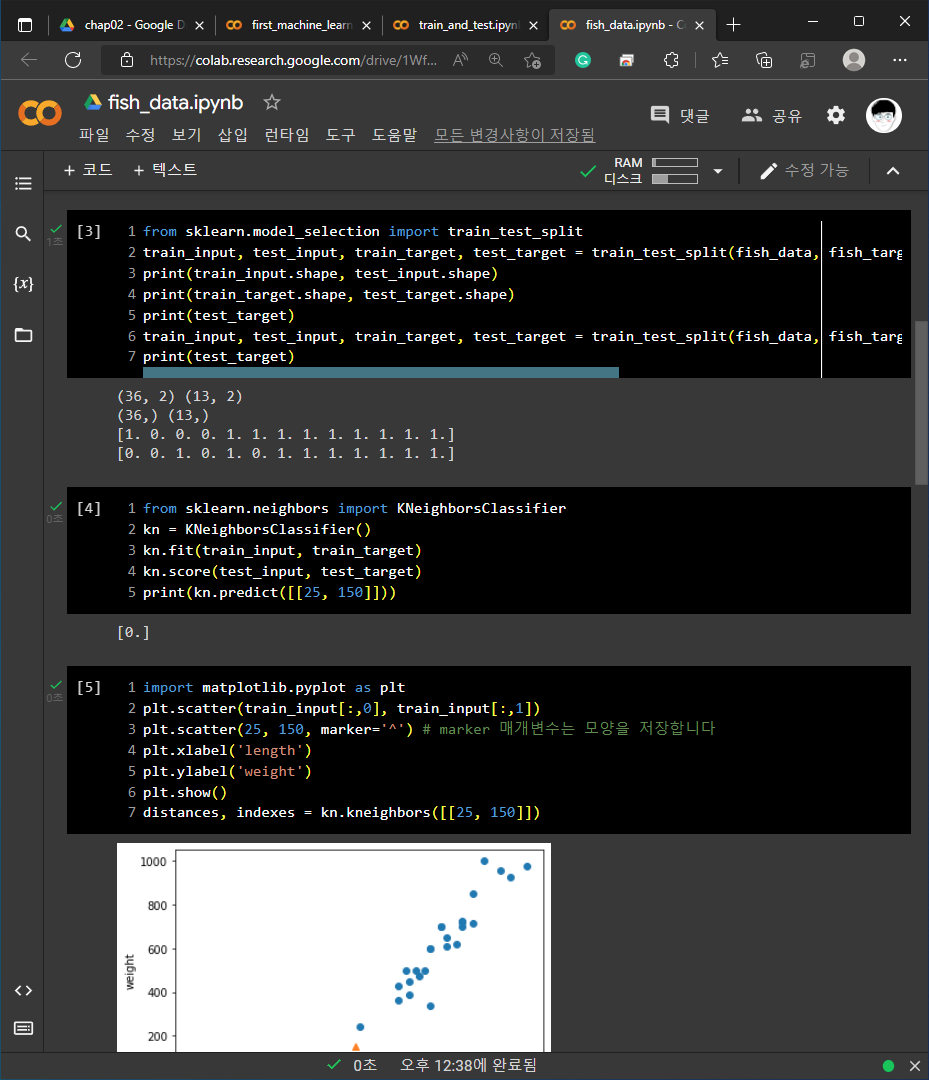
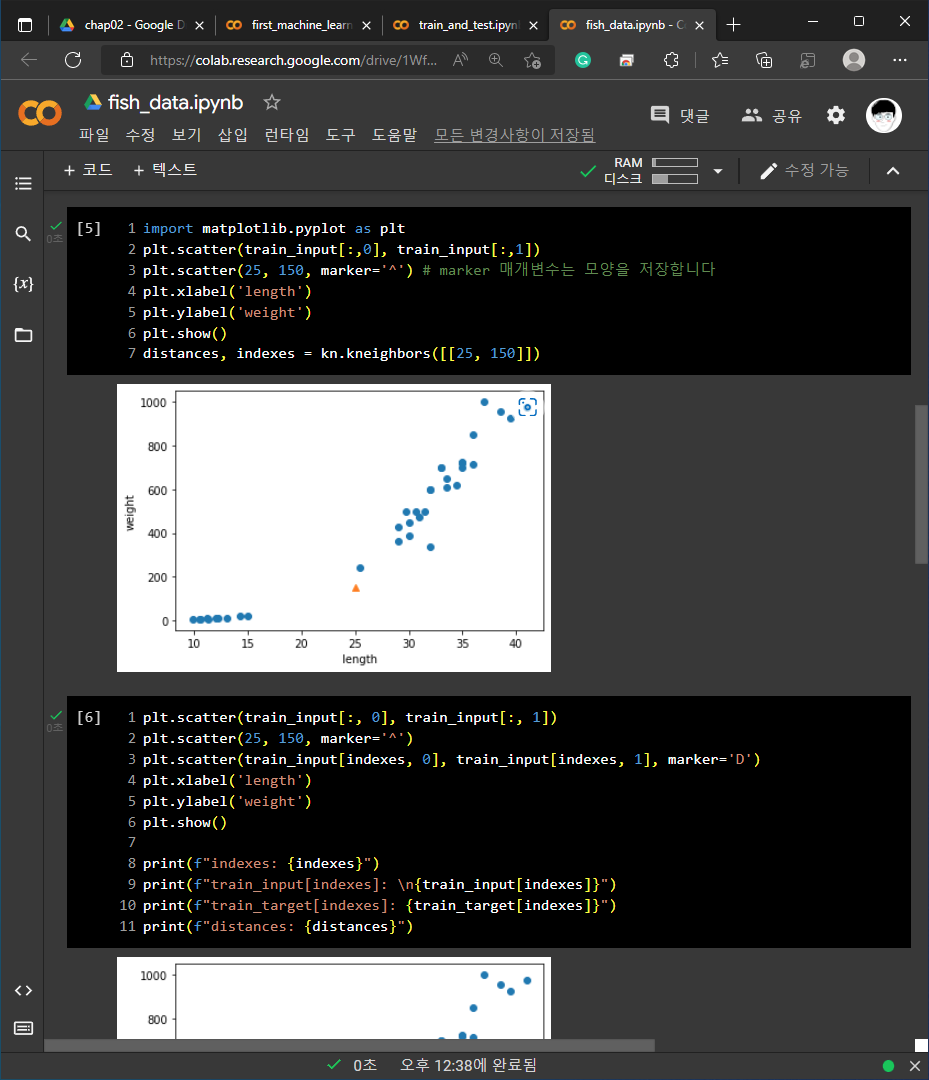
2. 기본 미션 - 코랩 실습 화면 캡쳐 하기
각 예제들에 대한 코랩 화면 캡쳐 입니다.
1) 01-3 손코딩

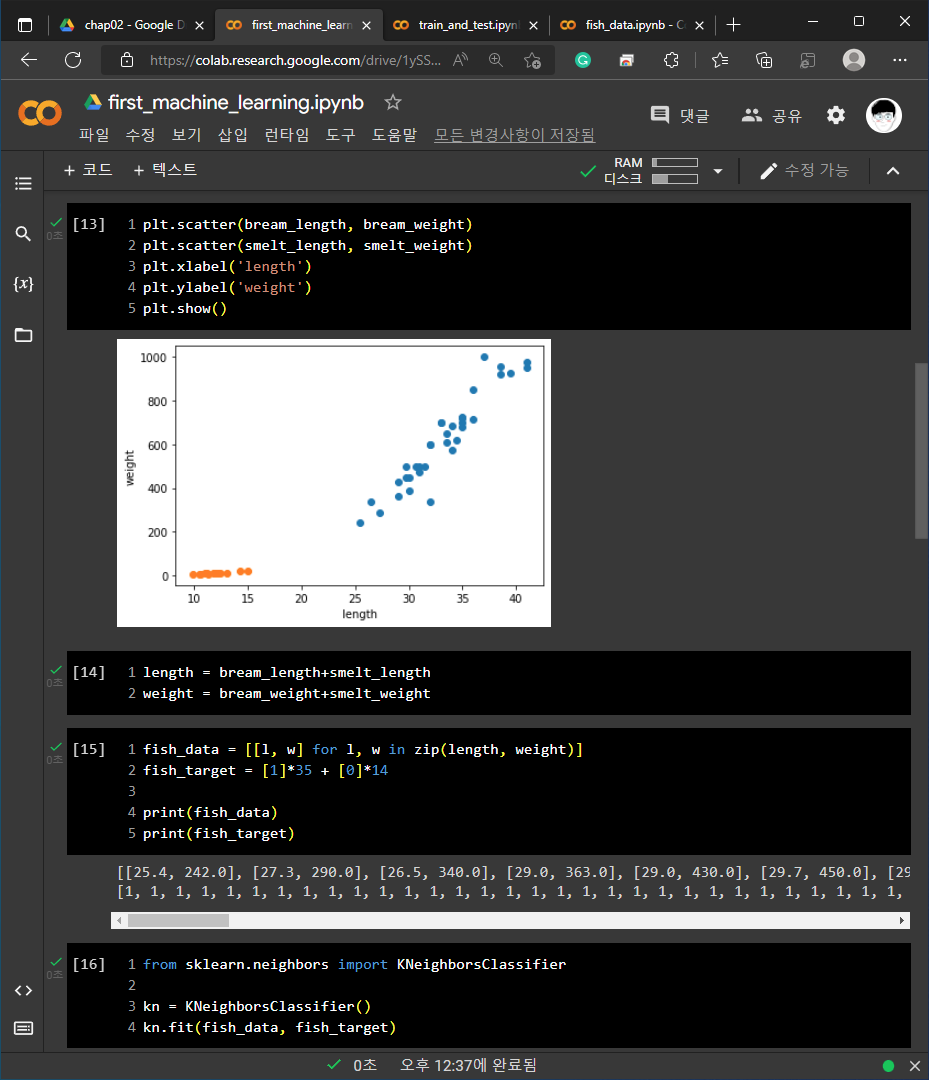
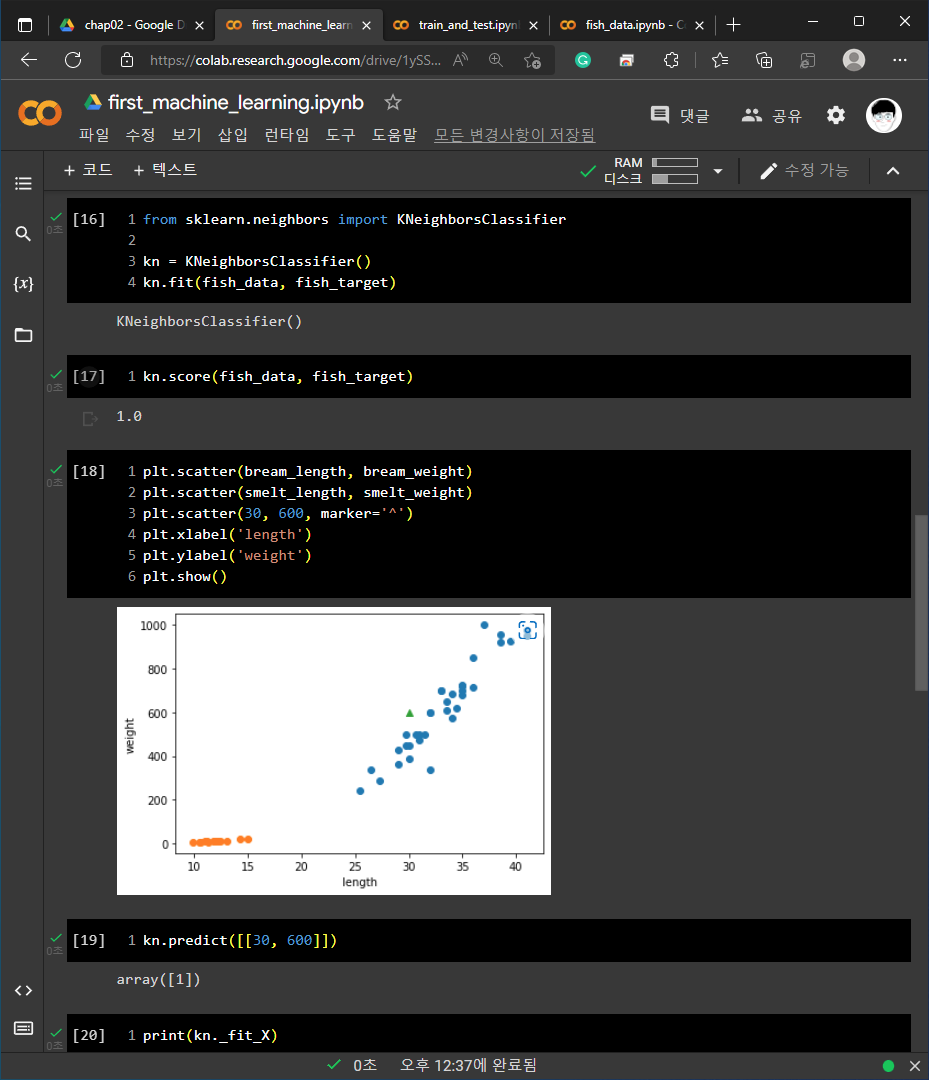
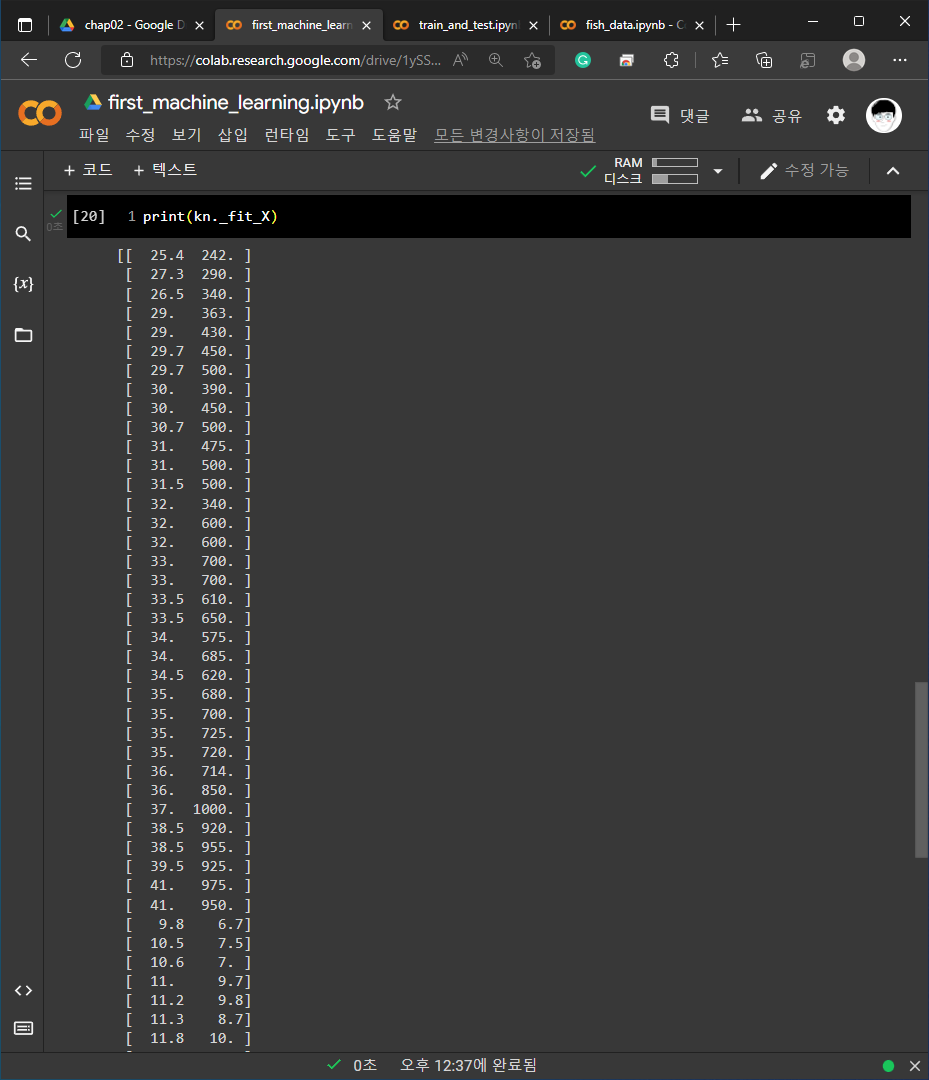
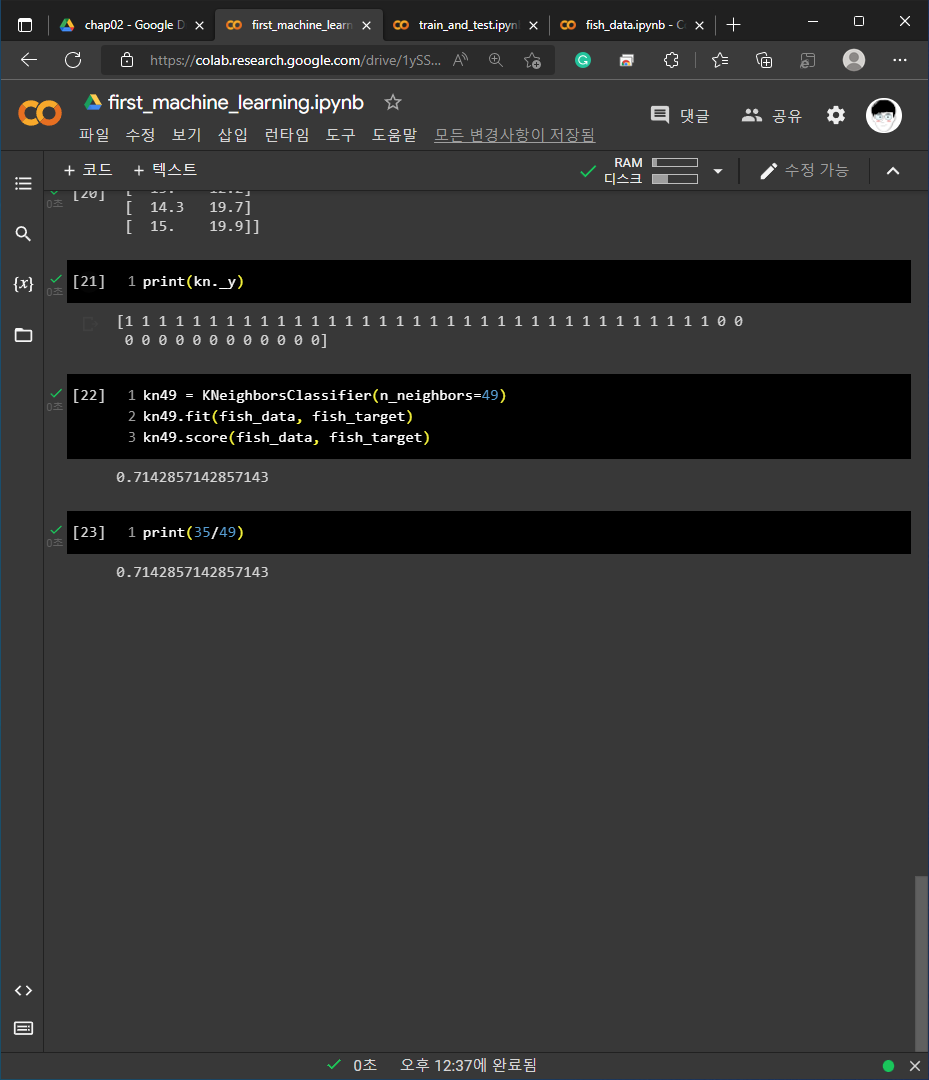
2) 02-1 손코딩
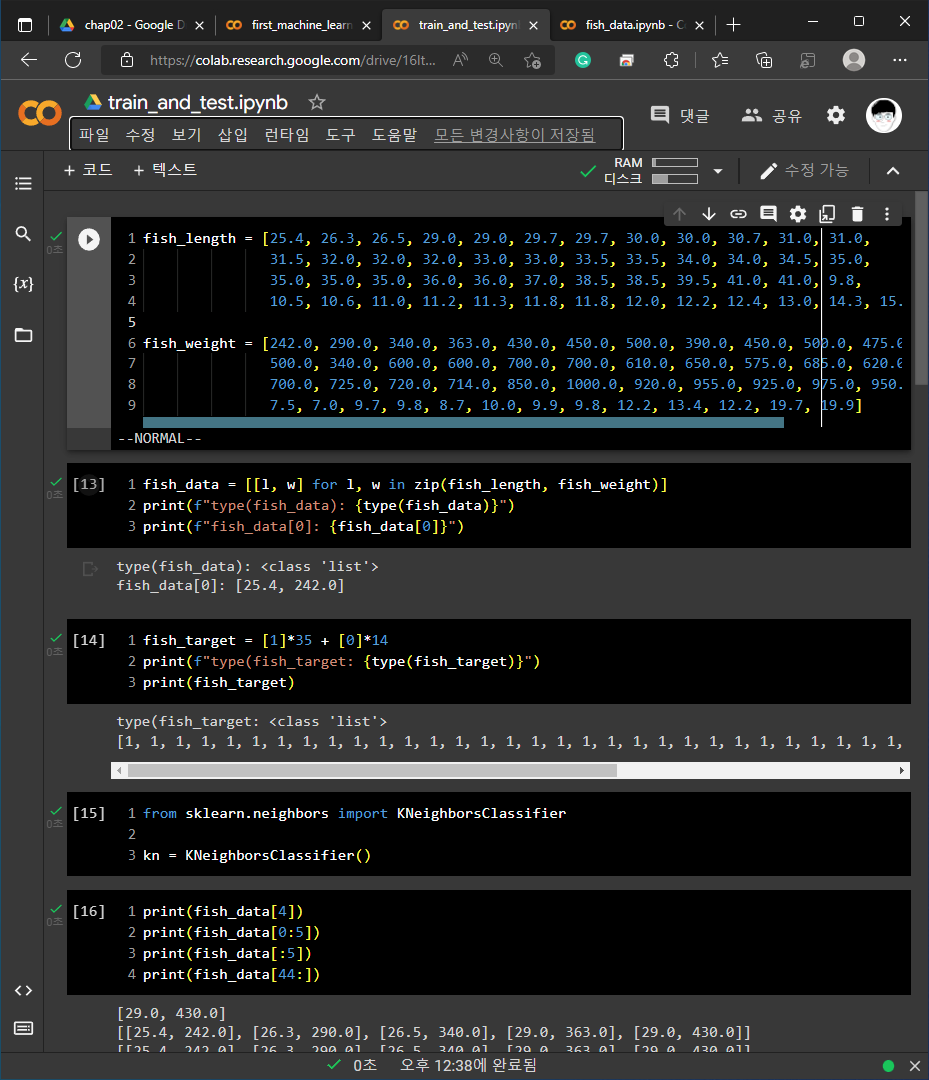
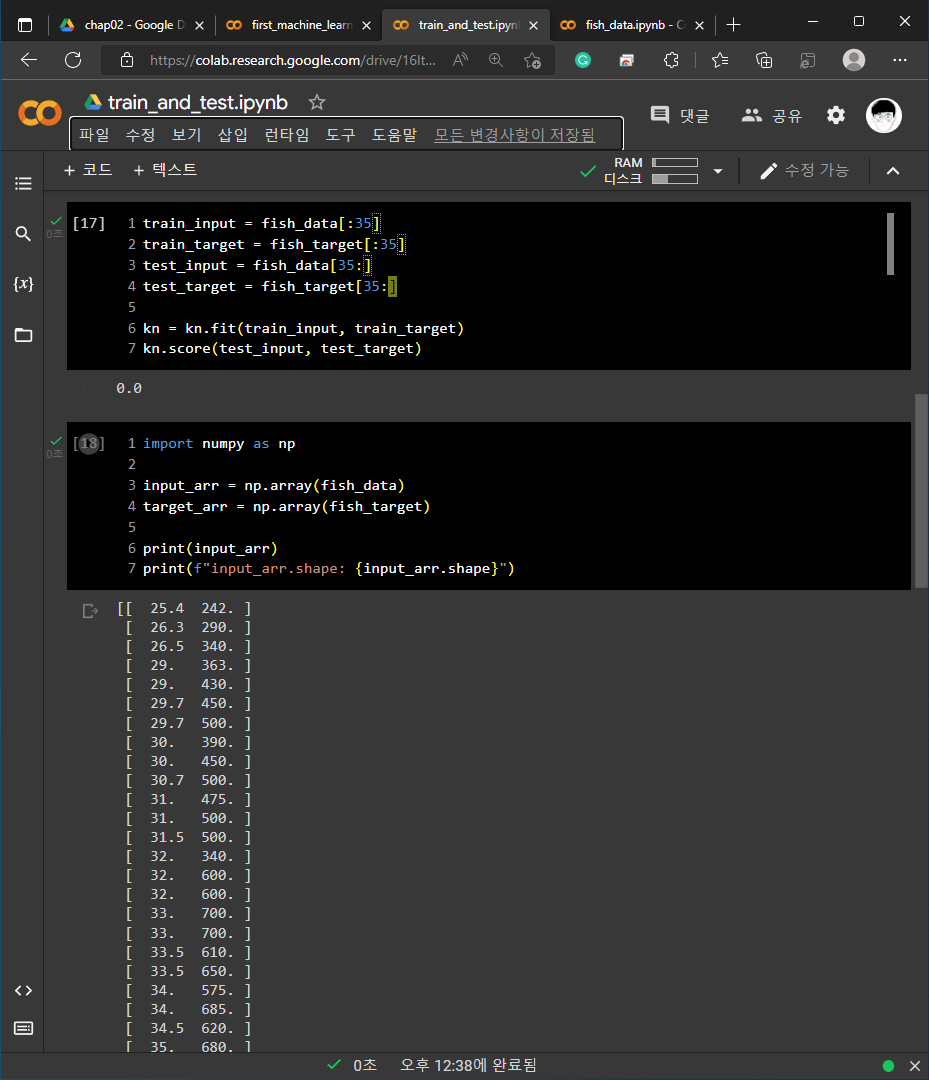
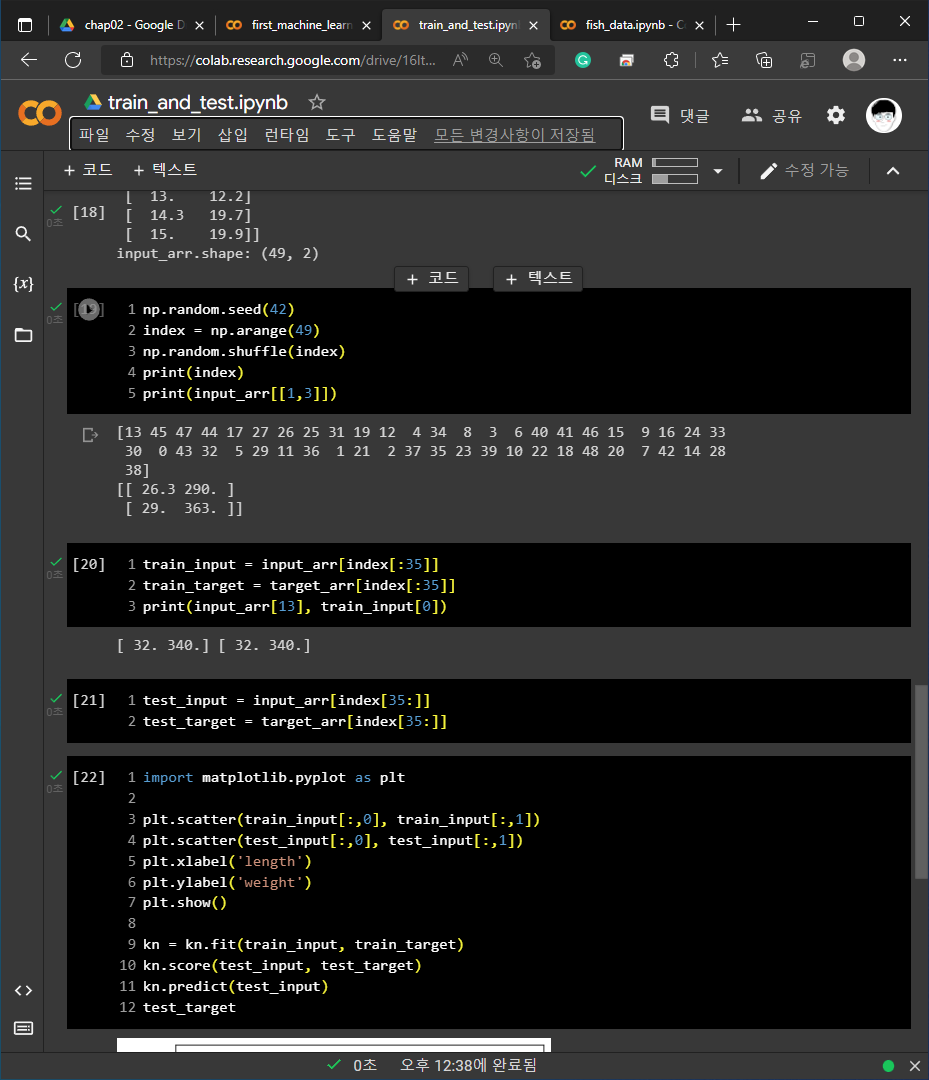
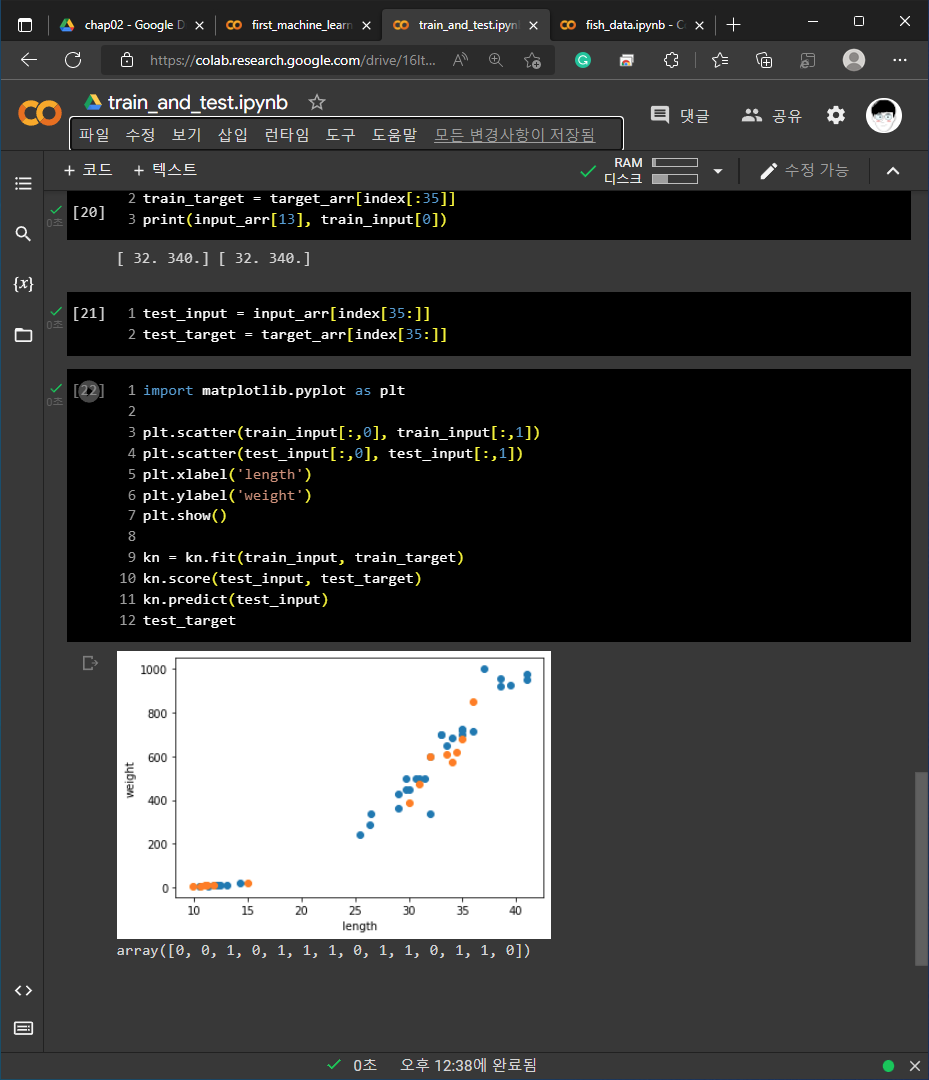
3) 02-2 손코딩
3. 선택 미션 - Ch.02(02-1) 확인 문제 풀고, 풀이 과정 정리하기
다음은 확인 문제의 풀이 입니다. (출처: 혼자 공부하는 머신러닝+딥러닝; 한빛미디어; 2020; 박해선 저)
1. 머신러닝 알고리즘의 한 종류로서 샘플의 입력과 타깃(정답)을 알고 있을 때 사용할 수 있는 학습 방법은 무엇인가요? 1) 지도 학습
1) 지도 학습 - 입력에 대한 타깃(정답)이 정해져 있고, 이 패턴을 학습한 후 알고리즘이 정답을 맞히는 학습입니다.
2) 비지도 학습 - 입력에 대한 타깃이 정해져 있지 않으며, 입력 데이터 안에서 데이터의 패턴을 파악하는데 도움이 됩니다.
3) 차원 축소
4) 강화 학습 - 입력에 대한 보상이 주어지는 것으로 이를 통해서 학습을 진행합니다.
+ 입력과 타깃으로 구성된 데이터를 훈련 데이터(training data)라고 부릅니다.
+ 입력에서 사용된 것들을 데이터의 특성(feature)이라고 부릅니다.
2. 훈련 세트와 테스트 세트가 잘못 만들어져 전체 데이터를 대표하지 못하는 현상을 무엇이라고 부르나요? 4) 샘플링 편향
1) 샘플링 오류
2) 샘플링 실수
3) 샘플링 편차
4) 샘플링 편향 - 훈련 세트와 테스트 세트에 샘플이 잘 섞여서 분배되지 않은 것을 의미합니다.
+ numpy.random.shuffle(index)를 사용하여서 데이터의 index를 섞어줄 수 있습니다.
+ from sklean.model_selection import train_test_split을 통해서 훈련 세트와 테스트 세트를 알고리즘의 도움을 받아서 섞어 줄 수 있습니다.
3. 사이킷런은 입력 데이터(배열)가 어떻게 구성되어 있을 것으로 기대하나요? 2) 행 : 샘플, 열 : 특성
1) 행 : 특성, 열 : 샘플
2) 행 : 샘플, 열 : 특성 - 사이킷런은 행에 샘플, 열에 특성이 구성되어 있을 것으로 기대합니다.
3) 행 : 특성, 열 : 타깃
4) 행 : 타깃, 열 : 특성
The samples matrix (or design matrix) X. The size of X is typically (n_samples, n_features), which means that samples are represented as rows and features are represented as columns.
- https://scikit-learn.org/stable/getting_started.html
긴 글 읽어주셔서 감사합니다.
글과 관련된 의견은 언제든지 환영입니다.
'책 이야기 > 스터디 기록' 카테고리의 다른 글
| [혼공머신] 딥러닝을 시작합니다 (0) | 2022.08.16 |
|---|---|
| [혼공머신] 비지도 학습 (0) | 2022.08.12 |
| [혼공머신] 트리 알고리즘 (0) | 2022.07.30 |
| [혼공머신] 다양한 분류 알고리즘 (0) | 2022.07.18 |
| [혼공머신] 회귀 알고리즘과 모델 규제 (0) | 2022.07.11 |




댓글